本文共 8482 字,大约阅读时间需要 28 分钟。
ActiveMQ的集群
内嵌代理所引发的问题:
- 消息过载
- 管理混乱
- Master slave
- Broker clusters
- MASTER/SLAVE模式
- Cluster模式
Pure Master Slave
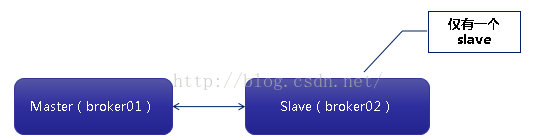
Pure master slave的工作方式:
当master broker失效的时候。Slave broker 做出了两种不同的相应方式
- 启动network connectors和transport connectors
- slave broker停止,slave broker只是复制了master broker的状态
failover://(tcp://masterhost:61616,tcp://slavehost:61616)?randomize=falsePure Master Slave具有以下限制:
- 只能有一个slave broker连接到master broker。
- 在因master broker失效后slave才接管(保证消息完全拷贝)
- 要想恢复master,停止slave,拷贝slave中的数据文件到master中,然后重启;
- Master broker不需要特殊的配置。Slave broker需要进行以下配置:
...
Shared File System Master Slave
如果你使用共享文件系统,那么你可以使用Shared File System Master Slave。如下图所示:
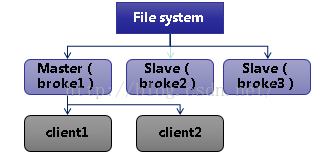
failover:(tcp://broker1:61616,tcp://broker2:6161 7,broker3:61618)
其中/sharedFileSystem是文件共享的系统文件目录…
JDBC Master Slave
JDBC Master Slave的工作原理跟Shared File System Master Slave类似,只是采用了数据库作为持久化存储
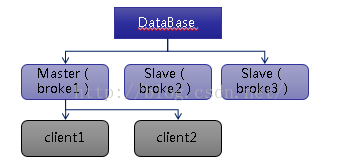
客户端调用:
failover:(tcp://broker1:61616,tcp://broker2:616167,broker3:61618)
Broker clusters-静态
Broker clusters ,网络型中介(network of brokers)连接到网络代理的两种方式:- 静态的方法配置访问特定的网络代理
- 发现中介(agents)动态的探测代理
Static:(uri1,uri2,uri3,…)?key=value 或是Failover:(uri1, … , uriN)?key=value 下面给出一个配置实例:
几种集群对比
- broker的集群在多个broker之前fail-over和 load-balance,master-slave能fail-over,但是不能load- balance
- 消息在多个broker之间转发,但是消息只存储在一个broker上,一旦失效必须重启,而主从方式master失效,slave实时备份消息。
- jdbc方式成本高,效率低
- master-slave方式中pure方式管理起来麻烦
Master/Slave集群搭建-传统式
一般activemq的Master Slave是基于KAHADB的阻塞来做的,先看一下原理
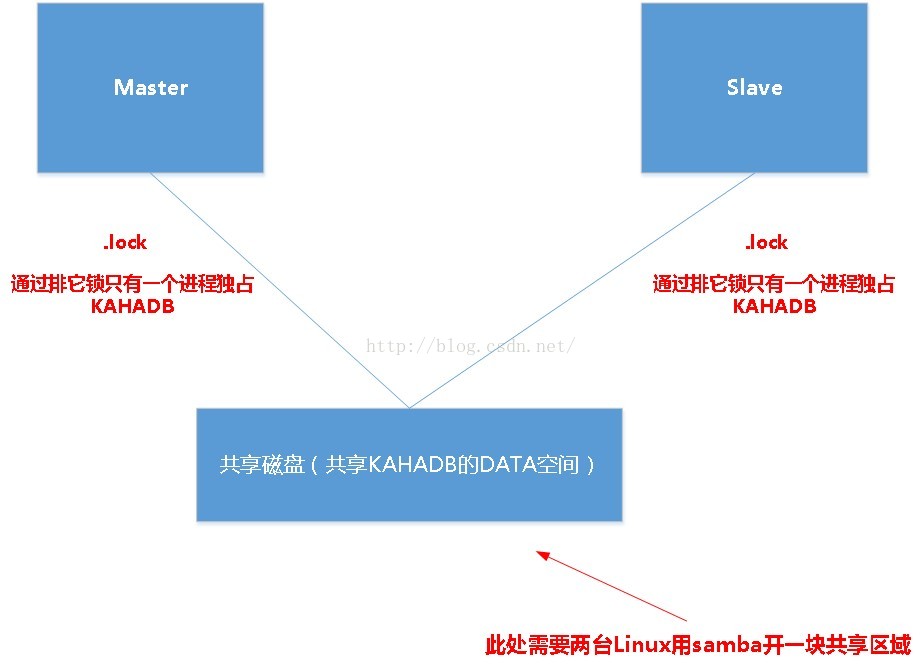
注意红色加粗的地方,这是传统的Master Slave的一个缺陷。这样做太不安全了!
下面给出核心配置:
master配置(不要忘了改conf目录下的jetty.xml文件中的端口)slave配置(不要忘了改conf目录下的jetty.xml文件中的端口)
- 把master conf 目录中的jetty.xml中的端口改成8161
- 把slave conf 目录中的jetty.xml中的端口改成8162
<kahaDB directory=“/localhost/kahadb”/>
中的db lock住,它就成了mater,而此时另一个实例会处于“pending”状态。当master宕机后slave会自动启动转变为master。当宕掉的master再次被启动后然后变成slave挂载在原先的slave下面变成slave’客户端的访问代码如下,只要改spring中的配置,代码层无需发动:Master/Slave集群搭建-基于ZooKeeper
搭个集群,还要共享磁盘???见了鬼去了,这种方案肯定不是最好的!
因此,从ActiveMQ5.10开始出现了使用ZooKeeper来进行Master/Slave搭建的模式。搭建时请务必注意下面几个问题:- 参于master slave组网的配置中<broker xmlns=“http://activemq.apache.org/schema/core” brokerName=“zk_cluster_nodes“必须一至。
- ActiveMQ至少需要3个实例(2N+1公式),只要不符合2N+1,master slave集群会发生集群崩溃
Master/Slave集群搭建-基于ZooKeeper搭建
搭建ZooKeeper,你可以搭建3个ZooKeeper实例也可以只用1个,如果出于高可用性考虑建议使用3台ZooKeeper。
下载ZK,我们在这边使用的是“zookeeper-3.4.6”,把它解压到Linux服务器上,在其conf目录下生成zoo1.cfg文件 ,内容如下:tickTime=2000initLimit=10syncLimit=5dataDir=/opt/zk/data/1clientPort=2181#server.1=127.0.0.1:2887:3887#server.2=127.0.0.1:2888:3888#server.3=127.0.0.1:2889:3889在ZK的data目录下建立一个目录,名为“1”,并在其下建立一个文件,文件名为“myid”并使其内容为1
如果你需要在本地搭建2N+1的ZooKeeper,那你必须依次在data目录下建立2、3两个文件夹并且在每个文件夹下都有一个myid的文件,文件的内容依次也为2,3,然后把下面注释掉的3行server.1 server.2 server.3前的#注释符放开。
因此data目录下的目录名和myid中的内容对应的就是server.x这个名字。tickTime=2000initLimit=10syncLimit=5dataDir=/opt/zk/data/1clientPort=2181server.1=127.0.0.1:2887:3887server.2=127.0.0.1:2888:3888server.3=127.0.0.1:2889:3889
按照2N+1,你必须至少建立3个ActiveMQ实例。在搭建前我们先来看一下我们的集群规划吧

本例中,我们只使用一个ZK节点,即2181端口来做MQ1-3的数据文件共享。
核心配置
以下是传统的Master/Slave配置基于ZK的配置
不要忘了,3个MQ实例的brokerName必须一致,要不然你会在集群启动时出现: Not enough cluster members when using LevelDB replication 这样的错误。 或者在集群启动后当master宕机slave被promote成master时发生集群崩溃。
依次把3台mq实例均配置成replicatedLevelDB即可,在此配置中有一个zkPath,笔者使用的是默认配置。你也可以自行加上如:
网上所有教程都没有说明这个zkPath到底是一个什么东西,害得一堆的使用者以为这是一个目录,以为用ZK做mq的集群也需要“共享”一块磁盘空间。 这个zkPath代表zookeeper内的“路径”,即你运行在2181端口的zk内的“寻址节点”,类似于JNDI。如果你没有这个zkPath,默认它在zk内的寻址节点为“/default”。加入到某一组master slave中的mq的实例中的zkPath必须完全匹配。 这边还有一个replicas=“3”的设置 ,这边的数字指的就是ActiveMQ实例的节点数,它需要满足2N+1,因此你也可以5台(1拖4)。
master slave一旦启动后,在客户端的配置就很简单了,如下:
你可以如此实验:
- 生产和消费分成两个程序。
- 生产发一条消息,注意看console会输出如“[INFO] Successfully reconnected to tcp://192.168.0.101:61616”
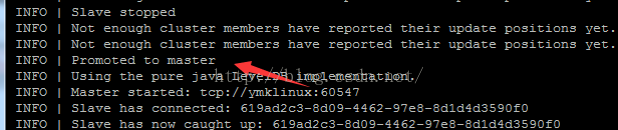
- 手工停止61616这台实例,然后你会发觉61617或者 是61618中有一台被promoted to master
- 然后运行consumer,consumer会连上被promoted的实例并继续消费刚才那3条消息


Master/Slave集群搭建-Broker Cluster搭建
所谓cluster即负载匀衡,它负载的是“用户”的请求,此处的用户就是调用端
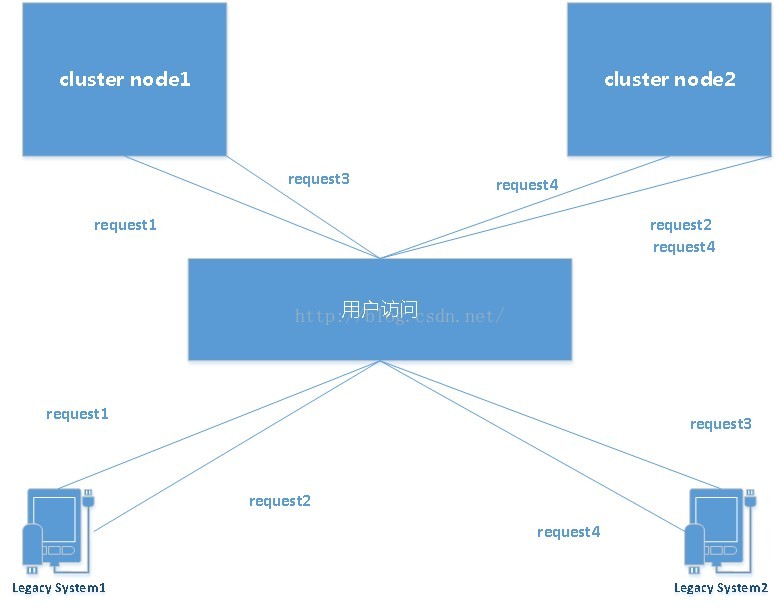
cluster的用法就是用来分散用户的“并发”请求的。前面説过,ActiveMQ的Cluster有两种:
- 动态式(multicast)
- 静态式(static)
Master/Slave集群搭建-Broker Cluster搭建方式
核心配置
请维持各cluste节点间不同的持久化方式(你也可以使用kahadb,但不要做成和master slave一样的排它锁方式啊。 在61616中的配置
在61617中的配置
客户端的配置
Master/Slave集群搭建-Broker Cluster和Master Slave对比
优点
- 自动分发调用端请求
- 流量分散
当调用端连接上任意一个节点发送了一条消息,比如说往NODE A发送了一条消息。
此时消费端还没来得及消费NODE A上的消息该节点就发生宕机了。此时调用端因为有failover所以它会自动连上另一个节点(NODE B)而该节点上是不存在刚才“发送的消息”的,因为刚才发送到NODE A的消息只在NODE A上,没有同步到NODE B上。
因为只有Master Slave会做主从间的消息同步,这是一个致命伤。具体实验步骤:- send一条消息到cluster,并观察send时连接的是哪个节点
- 直接把该节点进程杀掉
- 用消费端连上集群
- 观察消费端是否拿得到消息
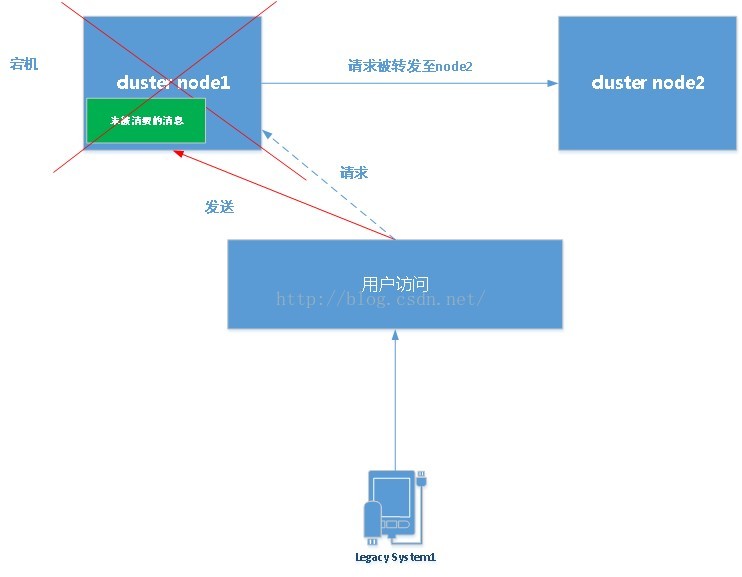
鱼与熊掌兼得法-完美解决方案
我们知道:
- master/slave模式下,消息会被逐个复制
- 而cluster模式下,请求会被自动派发
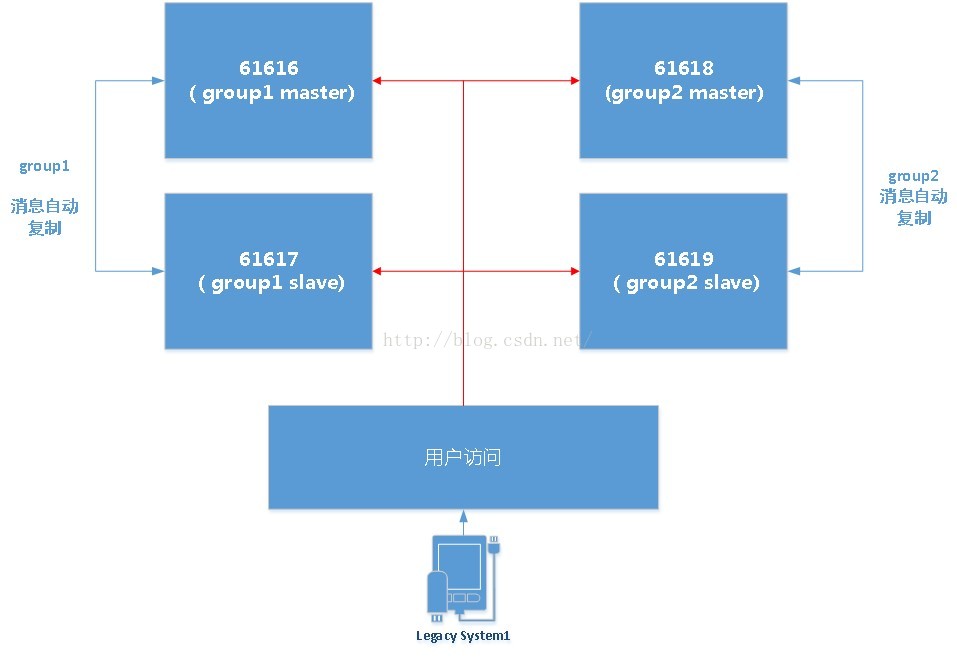
MASTER SLAVE+BROKER CLUSTER的搭建
- 我们使用ZK搭建MASTER SLAVE
- 我们使用BROKER CLUSTER把两个“组”合并在一起
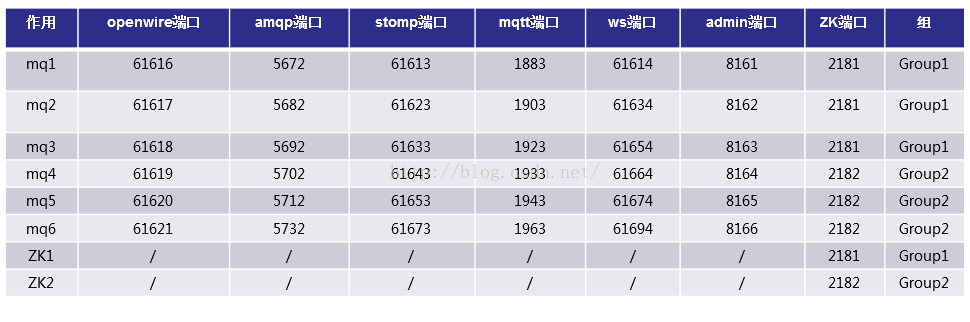
MASTER SLAVE+BROKER CLUSTER的搭建-Group1的配置
由于这涉及到两个组6个ActiveMQ的实例配置,如果把6个配置全写出来是完全没有必要的,因此我就把配置分成两组来写吧。每个组的配置对于其组内各个节点都为一致的,除去那些个端口号。Group1的配置(保持6个实例中brokerName全部为一致)
可以看到这边的broker cluster的配置是用来确保每一台都可以和Group2中的各个节点保持同步
MASTER SLAVE+BROKER CLUSTER的搭建-Group2的配置
可以看到这边的broker cluster的配置是用来确保每一台都可以和Group1中的各个节点保持同步
MASTER SLAVE+BROKER CLUSTER的搭建-客户端
客户端:
把6台实例全部启动起来(乖乖,好家伙)
把客户端写上全部6台实例(乖乖,好长一陀)
MASTER SLAVE+BROKER CLUSTER的搭建-实验
- 使用生产端任意发送3条消息。
- 生产端连上了61616,发送了3条消息,然后我们把61616所属的activemq1的进程直接杀了
- 然后运行消费端,消费端连上了61618,消费成功3条消息
- 先把所有实例进程全部杀掉
- 把6台实例全部启动起来(乖乖,好家伙)
- 把客户端写上全部6台实例(乖乖,好长一陀)
- 使用生产端任意发送3条消息。
- 生产端连上了61616,发送了3条消息,然后我们把61616所属的activemq1的进程直接杀了
- 然后运行消费端,消费端连上了61620,控台显示无任何消息消费
所谓的完美方案并不是真正的完美方案-情况A
是的,以上的方案存在着这一漏洞!来看原理!
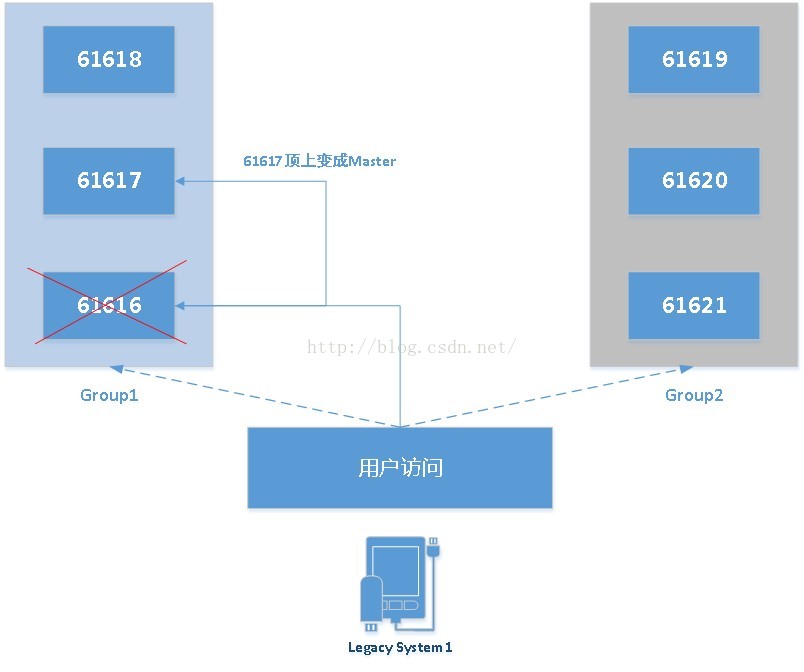
对于上述情况,当61616宕机后,如果此时请求被failover到了group1中任意一个节点时,此时消费端完全可以拿到因为宕机而未被消费掉的消费。
所谓的完美方案并不是真正的完美方案-情况B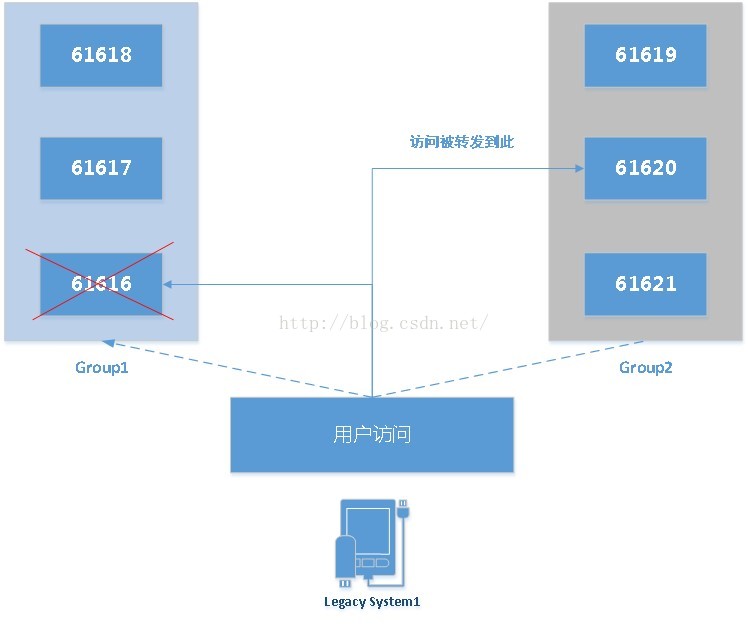
对于上述情况,当61616宕机后,如果此时请求被failover到了group2中任意一个节点时,此时因为group2中并未保存group1中的任何消息,因此只要你的请求被转发到另一个group中,消费端是决无可能去消费本不存在的消息的。这不是有可能而是一定会发生的情况。因为在生产环境中,请求是会被自由随机的派发给不同的节点的。
 我为什么要提这个缺点、要否认之前的篇章? 我就是为了让大家感受一下网上COPY复制还是错误信息的博文的严重性,那。。。怎么做是真正完美的方案呢。。。
我为什么要提这个缺点、要否认之前的篇章? 我就是为了让大家感受一下网上COPY复制还是错误信息的博文的严重性,那。。。怎么做是真正完美的方案呢。。。 如何让方案完美
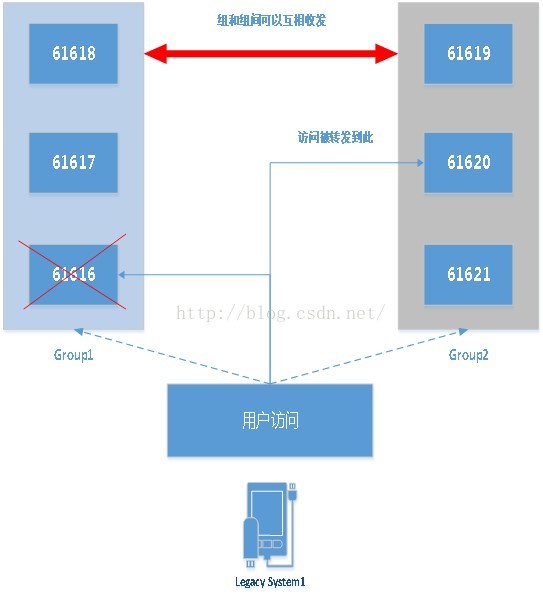
我们来看,如果我们把两个group间可以打通,是不是就可以在上述情况发生时做到failover到group2上时也能消费掉group1中的消息了呢?
怎么做?很简单,其实就是一个参数
duplex=true
什么叫duplex=true?
它就是用于mq节点间双向传输用的一个功能,看下面的例子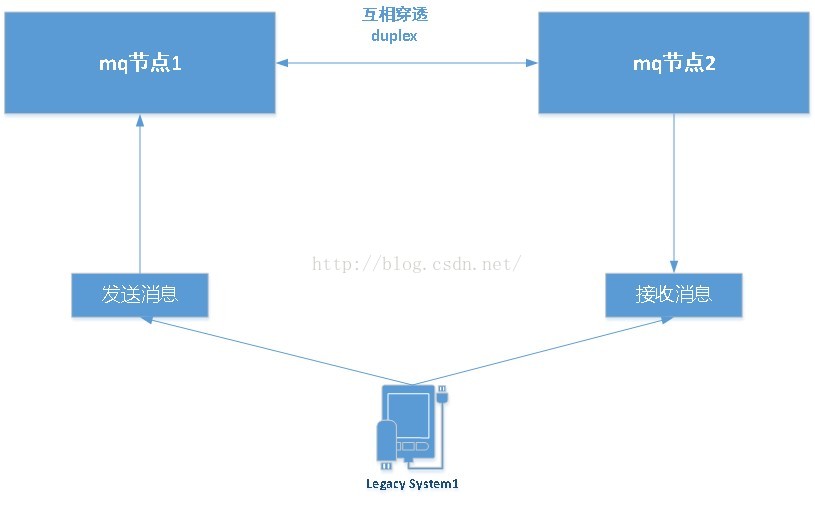
这就是duplex的使用方法,我很奇怪,竟然这么多人COPY 那错的1-2篇博文,但是就是没有提这个duplex的值,而且都设的是false。
duplex的作用就是mq节点1收到消息后会变成一个sender把消息发给节点2。此时客户如果连的是节点2,也可以消息节点1中的消息,因此我给它起了一个比英译中更有现实意义的名称我管它叫“穿透”。下面来看用“穿透机制”改造的真正完美方案吧。最终完美解决方案
考虑到消费端可能会发生:
当Group1中有未消费的数据时时,消费端此时被转派到了Group2中的任意一个节点。因此,在配置时需要进行如下的穿透: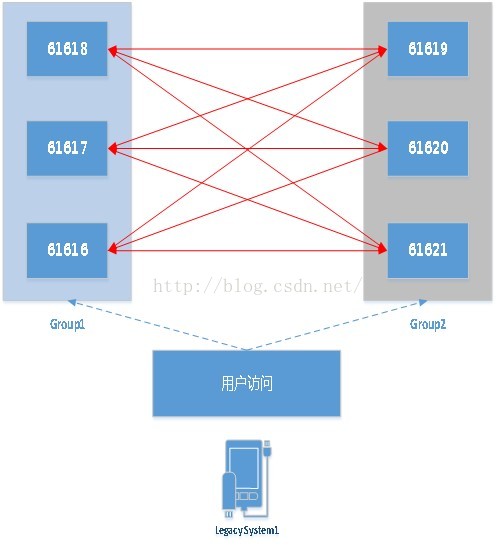
按照这个思路我们在各Group中的各节点中作如下配置即可:
Group1中的配置
Group2中的配置
Group2中的每一个节点都不再需要来一句以下这样的东西了:
因为,你设的是duplex=true,它相当于下面几行的效果:
现在知道为什么要duplex=true了吧!
验证
- 先把所有实例进程全部杀掉
- 把6台实例全部启动起来(乖乖,好家伙)
- 把客户端写上全部6台实例(乖乖,好长一陀)
- 使用生产端任意发送3条消息。
- 生产端连上了61619(属于Group2),发送了3条消息,然后我们把61619所属的activemq4的进程直接杀了
- 然后运行消费端,消费端连上了61616,控台显示消费成功3条消息
结束语
从生产环境的高可用性来説,如果需要使用完美解决方案的话我们至少需要以下这些实体机
2台实体机- 每台虚出3个子节点来(用VM),供3个MQ实例运行使用,2*3共为6个
- 并且一台实体机必须承载一个GROUP,同一个GROUP最好不要跨实体机或虚拟
- 每台虚出3个子节点来(用VM),供3个ZK 节点使用,2*3共为6个
- 并且一台实体机必须承载一个ZK GROUP,同一个ZK GROUP最好不要跨实体机或虚拟